Table of Contents
Using Regular Expression in Oracle Database
What are Regular Expressions?
Regular expressions help us to search a specific pattern in a string. The pattern can be Numeric, Char or Alpha-numeric.
Does Oracle support regex?
Oracle allows following types of characters to specify Regular Expression:
- Metacharacters
- Literals
Implementation of Regular Expression:
Oracle Database SQL Functions for Regular Expressions:
Oracle provides a group of SQL functions and conditions that support Regular Expression. These SQL functions help us to search and manipulating string data.
| Function/Condition | Category | Description |
|---|---|---|
| REGEXP_LIKE | Condition | What is the use of REGEXP_LIKE? It searches a character columns for a pattern. It can be used in the WHERE clause of query to get the matching rows of a regular expression. |
| REGEXP_REPLACE | Function | What is the use of REGEXP_REPLACE ? It search for a pattern in a character column and replace it with the value of the string specified. |
| REGEXP_INSTR | Function | What is the use of REGEXP_INSTR ? It searches a string for the given occurrence of a regular expression pattern and returns an integer, indicating the position where the match was found. |
| REGEXP_SUBSTR | Function | What is the use of REGEXP_SUBSTR ? It searches a regular expression pattern and returns a substring that matches the pattern. |
Regular Expression Metacharacters in Oracle Database:
Metacharacters are operators that specify search algorithm.
Metacharacters supported in Regular Expressions:
Oracle database allows following types of Metacharacters:
- POSIX Metacharacters
- Regular Expression Operator for Multilingual Enhancement
- Perl Influenced Extensions in Oracle Regular Expressions
POSIX Metacharacters in Oracle Database Regular Expression:
| Syntax | Operator Name | Description |
|---|---|---|
| . | Match Any Character – Dot operator | It matches any character in the given character set except NULL and new line character |
| + | One or more – Plus quantifier | It matches one or more occurrences of the preceding subexpression |
| ? | Zero or One – Question Mark quantifier | It matches zero or one occurrences of the preceding subexpression |
| * | Zero or more – Star quantifier | It matches zero or more occurrences of the preceding subexpression |
| {m} | Interval – Exact Count | It matches exactly m occurrences of the preceding subexpression |
| {m, } | Interval – At least Count | It matches at least m occurrences of the preceding subexpression |
| {m, n} | Interval – Between Count | It matches at least m, and not more than n occurrences of the preceding subexpression |
| [ … ] | Matching Character List | It matches any single character in the list within the bracket |
| [^ … ] | Non matching Character List | It matches any single character not in the list within the bracket |
| | | Or | It matches any of the alternatives |
| ( … ) | Subexpression or Grouping | Treats the operator within the bracket as a unit. The subexpression can be a string of literals or a complex expression containing operators |
| \n | Backreference | It matches the nth precedence subexpression what is grouped within parentheses, where n is an integer between 1 and 9. |
| \ | Escape Character | It treats the subsequent metacharacter as a literal. Use a backslash ( \ ) to search for a character that is normally treated as a metacharacter. |
| ^ | Beginning of Line Anchor | It matches the beginning of a string. For multiline cases it matches the beginning of any line within the source string |
| $ | End of Line Anchor | It matches the end of a string |
| [:class:] | POSIX character Class | Matches any character belonging to the specified POSIX character class |
| [.element.] | POSIX Collating Element Operator | Specifies a collating element to use in the regular expression |
| [=character=] | POSIX Character Equivalence Class | It matches all characters that are members of same character equivalence class |
Example of POSIX Metacharacters:
Match Any Characters — DOT Operator (.) :
SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, 'S');

SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, 'S.l');

SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, 'S..l');

One or More — Plus Operator (+) :
SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, 'll+');
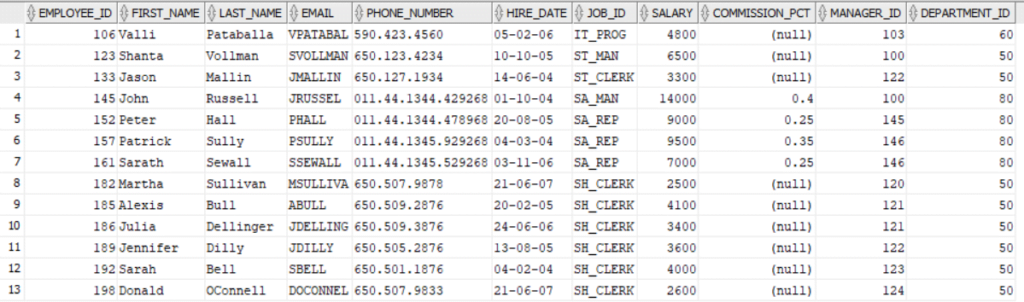
SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, 'lly+');

SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, 'ss+');

Zero or One — Question Mark Operator (?):
SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, 'kk');

SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, 'kk?');

In the above example, ? is placed after the 2nd k, so the query returns LAST_NAME where there is at least one or zero k followed by first k.
SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, 'key');

SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, 'key?');

In the above example, ? is placed after y, so the query returns the LAST_NAME where there is at least one or zero y followed by ke.
Zero or More — Star Quantifier (*):
SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, 're*n');

In the above example, the data set returns are, r preceded by zero or more e, preceded by n.
Inserting one row in EMPLOYEES table where LAST_NAME contains 3 z:
Insert into EMPLOYEES (EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,PHONE_NUMBER,HIRE_DATE,JOB_ID,SALARY,COMMISSION_PCT,MANAGER_ID,DEPARTMENT_ID) values (207,'William','Gietzzz','WGIETZZZ','515.123.8181',to_date('07-06-02','DD-MM-RR'),'AC_ACCOUNT',8300,null,205,110);
Interval — Exact Count ({m}):
SELECT * FROM EMPLOYEES
WHERE REGEXP_LIKE(LAST_NAME, 'e{2}');

In the above example, data set returns containing exactly 2 no of e.
SELECT * FROM EMPLOYEES
WHERE REGEXP_LIKE(LAST_NAME, 'z{3}');

In the above example data containing exactly 3 z.
Interval — At Least Count ({m, }):
SELECT * FROM EMPLOYEES
WHERE REGEXP_LIKE(LAST_NAME, 'k{1,}');

In the above example, the data set returns containing at least one k.
SELECT * FROM EMPLOYEES
WHERE REGEXP_LIKE(LAST_NAME, 'z{3,}');

In the above example data containing at least 3 z.
Interval — Between Count ({m, n}):
Inserting one row in EMPLOYEES table where LAST_NAME contains 3 z:
Insert into EMPLOYEES (EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,PHONE_NUMBER,HIRE_DATE,JOB_ID,SALARY,COMMISSION_PCT,MANAGER_ID,DEPARTMENT_ID) values (207,'William','Gietzzz','WGIETZZZ','515.123.8181',to_date('07-06-02','DD-MM-RR'),'AC_ACCOUNT',8300,null,205,110);
Querying data containing z between 1 and 3.
SELECT * FROM EMPLOYEES
WHERE REGEXP_LIKE(LAST_NAME, 'z{1,3}');

Matching Character List ([…]):
SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, '[avi]');

The above example returns the data set containing any single character of the group [avi] or all.
Non Matching Character List ([^…]):
SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID = 20;

SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID = 20 AND REGEXP_LIKE(LAST_NAME, '[^H]a');

In the above example data showing for DEPATMENT_ID 20, where LAST_NAME which is not started with H and followed by a.
SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID = 20 AND REGEXP_LIKE(LAST_NAME, '[^F]a');

In the above example data showing for DEPATMENT_ID 20, where LAST_NAME which is not started with F and followed by a.
SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID = 20 AND REGEXP_LIKE(LAST_NAME, '[^HF]a');

In the above example data showing for DEPATMENT_ID 20, where LAST_NAME which is not started with F or H and followed by a. No such data is available in this case.
Or (|):
SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID = 30;

SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID = 30 AND REGEXP_LIKE(LAST_NAME, '[R|B]a');

In the above example data showing LAST_NAME starts with either Ra or Ba.
SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID = 30 AND REGEXP_LIKE(LAST_NAME, '[T|Kh|C]o');

In the above example, query returns data, where LAST_NAME starts with either To, Kho or Co.
Subexpression or Grouping ( … ) :
SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID = 60;

SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID = 60 AND REGEXP_LIKE(LAST_NAME, '(st)');

In the above example data set returns that contains st in the LAST_NAME.
Backreference(\n):
SELECT * FROM EMPLOYEES WHERE DEPARTMENT_ID = 60;

SELECT REGEXP_REPLACE(A.PHONE_NUMBER, '([[:digit:]]{3})\.([[:digit:]]{3})\.([[:digit:]]{4})', '(\1 \2 - \3)') REGEX_PHONE_NUMBER, A.*
FROM EMPLOYEES A
WHERE A.DEPARTMENT_ID = 60;

In the above data set, new format has been provided to PHONE_NUMBER column with backreference operator.
Character (\):

SELECT REGEXP_REPLACE(A.JOB_ID, '\_', '-') REGEX_JOBID,
A.*
FROM EMPLOYEES A
WHERE A.DEPARTMENT_ID = 60;

In the above data set JOB_ID column, '_' has been replaced by '-' with Escape character.
Beginning of Line Anchor (^):
SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, '^Pat');

In the above example data set returns those data where LAST_NAME starts with Pat.
End of Line Anchor ($):
SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, 'an$');

In the above example data returns those data where LAST_NAME ends with an.
POSIX character Class ( [:class:] ):
UPDATE EMPLOYEES SET EMAIL = EMAIL||'@123' WHERE EMPLOYEE_ID IN (104, 105); 2 rows updated.
SELECT * FROM EMPLOYEES WHERE EMPLOYEE_ID IN (104, 105);

SELECT EMPLOYEE_ID,
LAST_NAME,
EMAIL,
REGEXP_SUBSTR(EMAIL, '[[:digit:]]{1}') DIGIT1,
REGEXP_SUBSTR(EMAIL, '[[:digit:]]{2}') DIGIT2,
REGEXP_SUBSTR(EMAIL, '[[:digit:]]{3}') DIGIT3,
REGEXP_SUBSTR(EMAIL, '[[:digit:]]{4}') DIGIT4
FROM EMPLOYEES
WHERE EMPLOYEE_ID IN (104, 105);

In the above example the data set returns the data which contains digit in EMAIL column. If you provide no of digit more than the digit available then null will be returned. Refer DIGIT4 column.
SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(LAST_NAME, '[[:blank:]]');

In the above example the data returns where LAST_NAME contains blank space.
UPDATE EMPLOYEES SET EMAIL = 'berNST@123' WHERE EMPLOYEE_ID = 104; 1 row updated.
SELECT * FROM EMPLOYEES WHERE REGEXP_LIKE(EMAIL, '[[:lower:]]');

In the above example the data returns where EMAIL contains lowercase letters.
SELECT * FROM EMPLOYEES
WHERE REGEXP_LIKE(LAST_NAME, '[[:upper:]]{2}');

In the above example the returns where 2 consecutive upper case letters exists in LAST_NAME column.
SELECT EMPLOYEE_ID,
LAST_NAME,
EMAIL,
REGEXP_SUBSTR(LAST_NAME, '[[:upper:]]') UPPER,
REGEXP_SUBSTR(LAST_NAME, '[[:upper:]]', 2) UPPER2
FROM EMPLOYEES
WHERE EMPLOYEE_ID IN (104, 105);

In the above example the data returns 1st and 2nd upper letter exists in LAST_NAME column of EMPLOYEE_ID 104 and 105. There is no second upper case letter exists in LAST_NAME Austin, so it returns null.
CREATE TABLE EMPLOYEES_TEST AS SELECT * FROM EMPLOYEES; ALTER TABLE EMPLOYEES_TEST ADD (REMARKS VARCHAR2(4000));
UPDATE EMPLOYEES_TEST SET REMARKS = 'Zipcode of '||LAST_NAME||' is '||REGEXP_SUBSTR(PHONE_NUMBER, '[[:digit:]]+', 9);
SELECT * FROM EMPLOYEES_TEST;

In the above example the REMARKS column is update with the string Zipcode of LAST_NAME is last 4 digit of PHONE_NUMBER column.
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
EMAIL,
PHONE_NUMBER,
REMARKS,
REGEXP_SUBSTR(REMARKS, '[[:digit:]]{4}') ZIPCODE
FROM EMPLOYEES_TEST;

In the above example digit characters were returned from REMARKS column as ZIPCODE.
POSIX Collating Element Operator ( [.element.] ) :
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
EMAIL,
JOB_ID
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, '[.kz.]');

In the above example the data set returns data where LAST_NAME contains either k or z or both.
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
EMAIL,
JOB_ID
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, '[.z.]');

In the above example the data set returns data where LAST_NAME contains at least one z.
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
EMAIL,
JOB_ID
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, '[aeiou]{3}');

In the above example the data set returns data where LAST_NAME contains consecutive 3 vowels.
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
EMAIL,
JOB_ID
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, '[aeiou]{2}');

In the above example the data set returns data where LAST_NAME contains consecutive 2 vowels.
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
EMAIL,
JOB_ID
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(JOB_ID, '^[F-I]');

In the above example the data set returns data where JOB_ID starts with characters from F to I.
POSIX Character Equivalence Class ( [=character=] ):
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
EMAIL,
JOB_ID
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, '[[=f=]]');

In the above example the data set returns data where LAST_NAME contains either lower or upper F.
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
EMAIL,
JOB_ID
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, '[[=z=]]');

In the above example the data set returns data where LAST_NAME contains either lower or upper Z.
Regular Expression Operator Multilingual Enhancements:
When Oracle REGEXP applied to multilingual data then POSIX operator extends beyond the matching capabilities of POSIX standard.
| Operator Syntax | Operator Name |
|---|---|
| ^ | Beginning of Line Anchor |
| $ | End of Line Anchor |
| . | Any Character — Dot |
| \n | Backreference |
| [ .. ] | Matching Character List |
| [ : : ] | POSIX Character Class |
| [ == ] | POSIX Character Equivalence Class |
Perl-Influenced Extensions in Oracle Regular Expressions:
Below table lists the Perl-influenced metacharacters supported in Oracle. These operators are not in the POSIX standard but are supported due to the popularity in PERL.
| Operator Syntax | Operator Name | Operator Description |
|---|---|---|
| \d | A digit character | It is equivalent to POSIX Class [[:digit:]] |
| \D | A non-digit character | It is equivalent to POSIX Class [^[:digit:]] |
| \w | A word character identified as alphanumeric or underscore character | it is equivalent to POSIX class [[:alnum]_] |
| \W | A nonword character | It is equivalent to POSIX class [[:alnum:]_] |
| \s | A whitespace character | It is equivalent to POSIX class [[:space:]] |
| \S | A non-whitespace character | It is equivalent to POSIX class [^[:space]] |
| \A | Only at the beginning of a string | In multiline mode that is when embedded new line characters in a string are considered the termination of a line \A does not match the beginning of each line. |
| \Z | Only at the end of a string or a newline ending a string. | In multiline mode that is when embedded new line characters in a string are considered the termination of a line \Z does not match the end of each line. |
| \z | Only at the end of a string | Its the absolute end of a string |
| *? | The preceding pattern element 0 or more times | This quantifier matches the empty string whenever possible. |
| +? | The preceding pattern element 1 or more times | |
| ?? | The preceding pattern element 0 or 1 time | |
| {n}? | The preceding pattern element exactly n times | This is equivalent to POSIX class {n} |
| {n, }? | The preceding pattern element at least n times | This is equivalent to POSIX class {n,} |
| {n,m}? | At least n but not more than m times | This is equivalent to POSIX class {n,m} |
A digit character:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
EMAIL,
PHONE_NUMBER,
REMARKS,
REGEXP_SUBSTR(REMARKS, '\d{4}') ZIPCODE
FROM EMPLOYEES_TEST;

A non-digit character:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
EMAIL,
PHONE_NUMBER,
REMARKS,
REGEXP_SUBSTR(REMARKS, '\D{4}') DESCRIPTION,
REGEXP_SUBSTR(REMARKS, '\D+') DESCRIPTION1
FROM EMPLOYEES_TEST;

In the above example DESCRIPTION and DESCRIPTION1 columns return the non-digit characters of REMARKS column.
A word character:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS,
REGEXP_SUBSTR(REMARKS, '\w+', 1, 1) DESCRIPTION,
REGEXP_SUBSTR(REMARKS, '\w+', 1, 2) DESCRIPTION1,
REGEXP_SUBSTR(REMARKS, '\w+', 1, 3) DESCRIPTION2,
REGEXP_SUBSTR(REMARKS, '\w+', 1, 4) DESCRIPTION3,
REGEXP_SUBSTR(REMARKS, '\w+', 1, 5) DESCRIPTION4
FROM EMPLOYEES_TEST;

In the above example the REMARKS column's individual words are extracted from the REMARKS column.
A nonword character:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS,
REGEXP_SUBSTR(PHONE_NUMBER, '\W', 1, 1) DESCRIPTION,
REGEXP_SUBSTR(REMARKS, '\W', 1, 1) DESCRIPTION
FROM EMPLOYEES_TEST;

In the above example DESCRIPTION columns returns the non-word characters like dot(.) and blank space.
A whitespace character:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS,
REGEXP_SUBSTR(PHONE_NUMBER, '\s', 1, 1) DESCRIPTION,
REGEXP_SUBSTR(REMARKS, '\s', 1, 1) DESCRIPTION1
FROM EMPLOYEES_TEST;

In the above example there is no white space in PHONE_NUMBER column so its returned null, while the REMARKS column contains spaces.
A non-whitespace character:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS,
REGEXP_SUBSTR(LAST_NAME, '\S+', 1, 1) DESCRIPTION,
REGEXP_SUBSTR(REMARKS, '\S+', 1, 1) DESCRIPTION1
FROM EMPLOYEES_TEST;
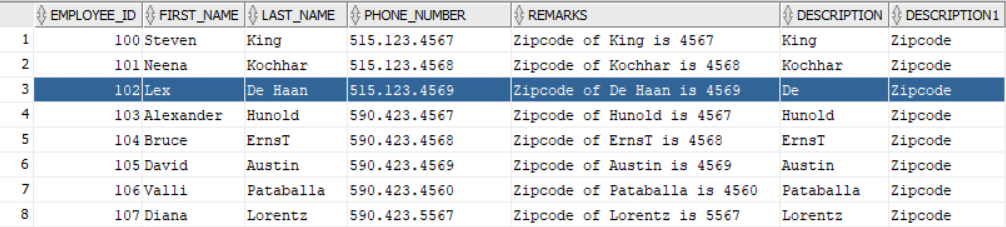
In the above example LAST_NAME De Haan has a space within the name, so it returns the De only, while from the REMARKS column its returned the 1st word before the 1st space.
Only at the beginning of a string :
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, '\AL+');

In the above example the data set returns all the LAST_NAME start with L.
Only at the end of a string:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, 'a\Z+');

In the above example the data set returns all the LAST_NAME ends with a.
The preceding pattern element 0 or more times:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, 'old*?');

In the above example the data set returns the data where LAST_NAME contains complete or partial part of old.
The preceding pattern element 1 or more times:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, 'old+?');

In the above example the data set returns the LAST_NAME contains one or more occurrences of string old.
The preceding pattern element 0 or 1 time:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, 'nson??');

In the above example the data set returns the data where LAST_NAME contains nson.
The preceding pattern element exactly n times:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, 's{2}?');

In the above data set returns the data where LAST_NAME contains 2 consecutive s.
The preceding pattern element at least n times:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, 'z{1,}?');

In the above example the data set returns data where LAST_NAME contains at least one z.
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, 'z{3,}?');

In the above example the data set returns data where LAST_NAME contains at least 3 z.
At least n but not more than m times:
SELECT EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
PHONE_NUMBER,
REMARKS
FROM EMPLOYEES_TEST
WHERE REGEXP_LIKE(LAST_NAME, 'z{1,3}?');

In the above example the data set returns the data where LAST_NAME contains z between 1 and 3.
Pattern Matching Modifiers:
| Modifiers Name | Modifiers Description |
|---|---|
| i | Case insensitive matching |
| c | Case sensitive matching |
| n | Allows the period(.), which by default does not match the new line, to match the new line character |
| m | Perform the search in multiline mode, the metacharacter ^ and $ signify the start and end respectively, of any line any where in the source string, rather than start and end of entire source string. |
| x | Ignores white space characters in the regular expression |
RELATED TOPICS: